Cross-Age Reference Coding for Age-Invariant Face Recognition and Retrieval
Bor-Chun Chen, Chu-Song Chen, Winston Hsu

Abstract
Recently, promising results have been shown on face recognition researches. However, face recognition and retrieval across age is still challenging. Unlike prior methods using complex models with strong parametric assumptions to model the aging process, we use a data-driven method to address this problem. We propose a novel coding framework called Cross-Age Reference Coding (CARC). By leveraging a large-scale image dataset freely available on the Internet as a reference set, CARC is able to encode the low-level feature of a face image with an age-invariant reference space. In the testing phase, the proposed method only requires a linear projection to encode the feature and therefore it is highly scalable. To thoroughly evaluate our work, we introduce a new large-scale dataset for face recognition and retrieval across age called Cross-Age Celebrity Dataset (CACD). The dataset contains more than 160,000 images of 2,000 celebrities with age ranging from 16 to 62. To the best of our knowledge, it is by far the largest publicly available cross-age face dataset. Experimental results show that the proposed method can achieve state-of-the-art performance on both our dataset as well as the other widely used dataset for face recognition across age, MORPH dataset.Publication
-
Bor-Chun Chen, Chu-Song Chen, Winston H. Hsu. Cross-Age Reference Coding for Age-Invariant Face Recognition and Retrieval, ECCV 2014 [Pdf] [Bibtex]
@inproceedings{chen14cross,
Author = {Bor-Chun Chen and Chu-Song Chen and Winston H. Hsu},
Booktitle = {Proceedings of the European Conference on Computer Vision ({ECCV})},
Title = {Cross-Age Reference Coding for Age-Invariant Face Recognition and Retrieval},
Year = {2014}
} -
Bor-Chun Chen, Chu-Song Chen, Winston H. Hsu. Face Recognition using Cross-Age Reference Coding with Cross-Age Celebrity Dataset, IEEE Transactions on Multimedia, 2015. (accepted) [pdf]
Dataset
Please notice that this dataset is made available for academic research purpose only. All the images are collected from the Internet, and the copyright belongs to the original owners. If any of the images belongs to you and you would like it removed, please kindly inform us, we will remove it from our dataset immediately.
Cross-Age Celebrity Dataset (CACD)
Cross-Age Celebrity Dataset (CACD) contains 163,446 images from 2,000 celebrities collected from the Internet. The images are collected from search engines using celebrity name and year (2004-2013) as keywords. We can therefore estimate the ages of the celebrities on the images by simply subtract the birth year from the year of which the photo was taken. The downloaded dataset contain two MATLAB structures:- celebrityData - contains information of the 2,000 celebrities
- name - celebrity name
- identity - celebrity id
- birth - celebrity brith year
- rank - rank of the celebrity with same birth year in IMDB.com when the dataset was constructed
- lfw - whether the celebrity is in LFW dataset
- celebrityImageData - contains information of the face images
- age - estimated age of the celebrity
- identity - celebrity id
- year - estimated year of which the photo was taken
- feature - 75,520 dimension LBP feature extracted from 16 facial landmarks
- name - file name of the image
- The dataset metadata and features used in this paper can be downloaded [here] (4.4G)
- The dataset metadata only can be downloaded [here] (817K)
- Original face images (detected and croped by openCV face detector) can be downloaded [here] (3.5G)
- 16 faical landmark locations used in this paper can be downloaded [here] (24M) (extracted by Intraface)
Notes
*we manually removed noisy images from celebrities with rank smaller or equal to five. However, since some of the images are hard to identify even for humans, the dataset might still contains small noises. Also, we only employ very simple duplicate detection method, so the dataset might still contain near-duplicate images.*Images of other celebrities (with rank higher than five) will contain noises, so they should not be use for evaluation.
*The dataset is mainly designed for cross-age face recognition and retrieval. The year labels in the CACD dataset is rough and thus we do not suggest to apply it to age-estimation works.
Verification Subset (CACD-VS)
We manually selected 2,000 positive cross-age image pairs and 2,000 negative pairs to form a subset for face verification task similar to the one used is LFW. The image pairs are carefully annotated by checking image content with surrdening text in the web pages. We evaluate the human preformance on this subset using Amazon Mechnical Turks.The dataset contains 4,000 image pairs divided by ten folds. Identities in each fold are mutually exclusive. The images are named as pairId_0.jpg and pairId_1.jpg for each pair. First 400 image pairs [(0000_0.jpg,0000_1.jpg) - (0399_0.jpg,0399_1.jpg)] are first fold, in which first 200 image pairs (i.e. 0000 - 0199) are positive pairs and second 200 image pairs (i.e. 0200 - 0399) are negative pairs. The second fold contains image pair (0400 - 0799) and so on.
Experimental Results
Face retrieval performance on CACD
Here we report the results using raw features (High-dimensional LBP) and the proposed methods (CARC) on face retrieval with three different subsets. In all three subsets, images taken in 2013 are used as query images. The database contains images taken in 2004-2006, 2007-2009, 2010-2012 for each of the three subsets respectively. All three subsets contains only images of celebrities with rank from 3 to 5.| Database | 2004-2006 | 2007-2009 | 2010-2012 | |||
| Methods | MAP | p@1 | MAP | p@1 | MAP | p@1 |
| High-Dimensional LBP | 36.6% | 78.0% | 38.9% | 80.3% | 44.0% | 85.5% |
| Cross-Age Reference Coding | 52.9% | 88.8% | 55.5% | 88.5% | 61.1% | 92.2% |
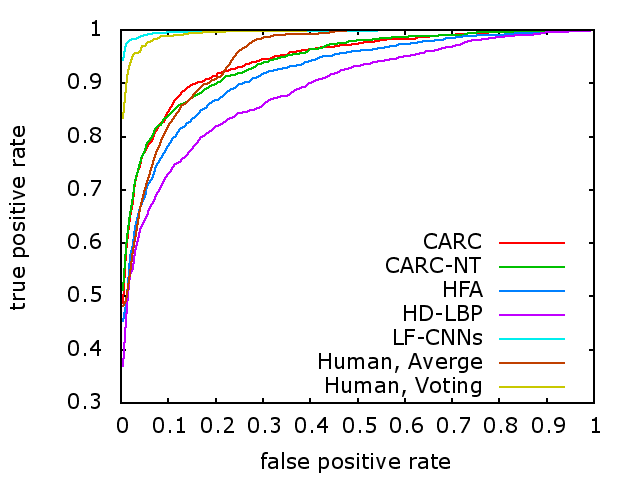
Face verification performance on CACD-VS
| Method | AUC |
| High-Dimensional LBP [1] | 88.8% |
| Hidden Factor Analysis [2] | 91.7% |
| Cross-Age Reference Coding [3] | 94.2% |
| LF-CNNs [4] | 99.3% |
| Human, Average [3] | 94.6% |
| Human, Voting [3] | 99.0% |
ROC Curve on CACD-VS
Reference
1. D.Chen,X.Cao,F.Wen,andJ.Sun,“Blessingofdimensionality:High- dimensional feature and its efficient compression for face verification,” in IEEE Conf. Computer Vision and Pattern Recognition, 2013, pp. 3025– 3032.2. D. Gong, Z. Li, D. Lin, J. Liu, and X. Tang, “Hidden factor analysis for age invariant face recognition,” in IEEE Int. Conf. Computer Vision, 2013.
3. Chen, Bor-Chun, Chu-Song Chen, and Winston H. Hsu. "Face recognition and retrieval using cross-age reference coding with cross-age celebrity dataset." IEEE Transactions on Multimedia 17.6 (2015): 804-815.
4. Wen, Yandong, Zhifeng Li, and Yu Qiao. "Latent factor guided convolutional neural networks for age-invariant face recognition." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
If you use our dataset and would like to report your results, please e-mail Sirius Chen. We will be gald to put your results on this webstie.
FAQ
- How do I access the annotated images in the CACD dataset?
- The celebrities with rank 1-5 are annotated. Celebrities with rank 1-2 (totally 80 celebrities) are used for valiadation, use celebrityImageData.name{find(celebrityImageData.rank <= 2)} to access the file names of these images; celebrities with rank 3-5 (totally 120 celebrities) are used for testing, use celebrityImageData.name{find(celebrityImageData.rank > 2 && celebrityImageData.rank <=5)} to access the file names.
Please contact Sirius Chen for any questions/problems/bug reports/etc.